


Most of my One Model work involves chatting with People Analytics professionals discussing how our technology enables them to perform their role more effectively. One Model is widely acknowledged for our superior ability to orchestrate and present customer’s people metrics, as well as leveraging Artificial Intelligence/Machine Learning for predictive modeling purposes. My customer interactions always result in excited conversations around our data ingestion and modeling, and how a customer can leverage the flexibility of our many presentation options. However, when it comes to further exploring the benefits of Artificial Intelligence, enthusiasm levels often diminish, and customers become hesitant to explore how this valuable technology can immediately benefit their organization.
One Model customer contacts tend to be HR professionals. My sense is they view Artificial Intelligence/Machine Learning as very cool, but aspirational for both them and their organization. This is highlighted during implementations as we plan their launch and roll-out timelines; the use of predictive models is typically pushed out to later phases. This results in a delayed adoption of an extraordinarily valuable tool.
Machine Learning is a subset of Artificial Intelligence and is the ability for algorithms to discern patterns within data sets. It elevates decision-support functions to an advanced level and as such can provide previously unrecognized insights. When used with employee data there is understandable sensitivity because people's lives and careers risk being affected. HR professionals can successfully use Machine Learning to address a variety of topics that impact an array of areas throughout their company. Examples would include:
- Attrition Risk – impact at the organizational level
- Promotability – impact at the employee level
- Candidate Matching – impact outside the organization
- Exploratory Data Analysis - quickly build robust understandings of any dataset/problem
With this basic understanding, let us explore three possible reasons why the deployment of Machine Learning is delayed, and how One Model works to increase a customer’s comfort level and accelerate its usage.
#1: Machine Learning is undervalued
For many of us, change is hard. There are plenty of stories in business, sports, or government illustrating a refusal to use decision-support methods to rise above gut-instinct judgments. The reluctance or inability to use fact-based evidence to sway an opinion makes this the toughest category to overcome.
#2: Machine Learning is misunderstood
For many of us, numbers and math are frightening. Typically, relating possibility and probability to a prediction does not go beyond guessing at the weather for this weekend’s picnic. Traditional metrics such as employee turnover or gender mix are simple and comfortable. Grasping how dozens of data elements from thousands of employees can interact to lead or mislead a prediction is an unfamiliar experience for many HR professionals that they would prefer to avoid.
#3: Machine Learning is intimidating
This may be the most prevalent reason, albeit subliminal. Admitting a weakness to colleagues, your boss, or even yourself is not easily done. Intimidation may arise from several sources. The first occurs from the general lack of understanding referenced earlier, accompanied by a fear of liability due to data bias or unsupported conclusions. Often, some organizations with data scientists on staff may pressure HR to transfer the responsibility for People Analytics predictions to these scientists to be handled internally with Python or R. This sort of internal project never ends well for HR; it is a buy/build situation akin to IT departments wanting to build their own People Analytics data warehouse with a BI front-end. Interestingly, when a customer’s data science team is exposed to One Model’s Machine Learning capabilities, they usually become some of our biggest advocates.
During my customer conversations, I avoid dwelling on their reluctance and simply explain how One Model’s One AI component intrinsically addresses Machine Learning within our value proposition. Customers do not need familiarity with predictive modeling to enjoy these benefits. Additionally, I explain how One AI protects our customers by providing complete transparency in how training data is selected, results are generated, how any models are making decisions, validating the strength of resulting prediction, and thorough flexibility to modify every data run to fit within each customer’s own data ethics. This transparency and flexibility provide protection against data bias and generally bad data science. Customers simply apply an understanding of their business requirements to One AI’s predictions and adjust if necessary. Below is a brief explanation of a few relevant components of One Model's Machine Learning strategy and the benefits they provide.
Selection of Training Data
After a prediction objective is defined, the next step is to identify and collect the relevant data points that will be used to teach One AI how to predict future or unseen data points. This can be performed manually, automatically, or a combination of both. One AI offers automatic feature selection using algorithms to decide which features are statistically significant and worth training upon. This shrinks the data set and reduces noise. The context of fairness is critical, and it is at this point that One AI starts to measure and report on data bias. One measurement of group fairness that One AI supports is Disparate Impact. Disparate Impact refers to practices that adversely affect one group of people of a protected characteristic more than another, even if a group does not overtly discriminate (i.e. their policies may be neutral). Disparate Impact is a simple measure of group fairness and does not consider sample sizes, instead focusing purely on outcomes. These limitations work well with attempting to prevent bias from getting into Machine Learning. It is ethically imperative to measure, report and prevent bias from making its way into Machine Learning. This Disparate Impact reporting is integrated into One AI along with methods to address the identified bias. One AI allows users to measure group fairness in many ways and on many characteristics at once, making it easy to make informed, ethical decisions.
Promotability predictions could serve as an example. If an organizations historic promotion data is collected for training purposes, the data set may reflect a bias toward Caucasian males who graduated from certain universities. Potential bias toward gender and race may be obvious, but there may also be a hidden bias toward these certain universities, or away from other universities that typically target different genders or race. An example of how hidden bias affected Amazon can be found here.
One AI can identify bias and help users remove bias from data using the latest research. It is important to One Model that our users not only be informed of bias but can also act upon these learnings.
Generation of Results
After a predictive model is run, One AI still takes steps that ensure the predictions are as meaningful as possible. It is important to note that One AI does all the “heavy lifting”; our customers need only provide oversight as it applies to their specific business. Any required modifications or changes are easily handled.
An example can be found in an Attrition Risk model. After running this model our Exploratory Data Analysis (EDA) report provides an overview of all variables considered for the model and identifies which were accepted, which were rejected, and why. A common reason for rejection is that of a “cheating” variable. This is when there is too close of a one-to-one relationship between the target and identified variable. If “Severance Pay” is rejected as a cheating variable, we likely will agree because logically anyone receiving a severance package would be leaving the company. However, if “Commute Time 60+” is rejected as a cheating variable, we may push back and decide to include this because commuting over an hour is something the organization can control. It is an easy modification to override the original exclusion and re-run the model.

One Model customers who are more comfortable with predictive modeling may even choose to dive deeper into the model itself. A report on each predictive run shows which model type was used, Dataset ID’s, Dimensionality Reduction status, etc. One Model’s flexibility allows a customer to change these with a mouse click should they want to explore different models. Please remember that this is not a requirement at all and simply a reflection of the available transparency and flexibility for those customers preferring this level of involvement.

My favorite component of our results summary reporting is how One AI ranks the variables impacting the model. Feature Importance is listed in descending order of importance to the result. In our Attrition Risk model above, the results summary report would provide a prioritized list of items to be aware of in your attempt to reduce attrition.
Strength of Prediction
It is important to remember that Machine Learning generates predictions, not statements of fact. We must realize that sometimes appropriate data is just not available to generate meaningful predictions and these models would not be trustworthy. Measuring and reporting the strength of predictions is a solid step in developing a data-driven culture.
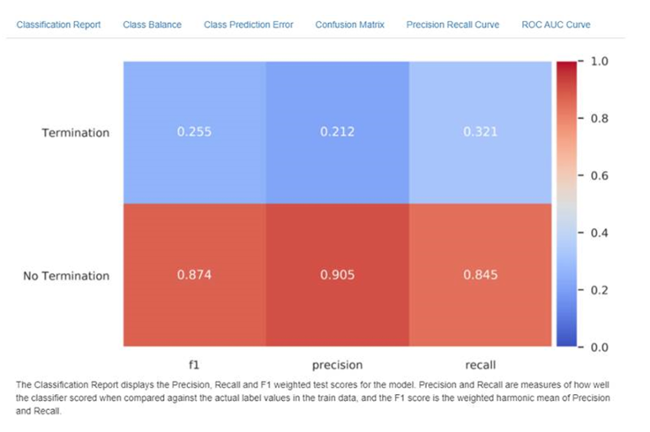
There are several ways to evaluate model performance; many are reflected in the graphic below. One Model automatically generates multiple variations to help provide a broad view and ensure that a user has the data they feel comfortable evaluating. Both “precision” and “recall” are measured and displayed. Precision measures the proportion of positive identifications (people who terminate in the future) the model correctly identified. Put another way when the model said someone would terminate, how often was it correct? Recall reflects the proportion of actual positives (people who terminate in the future) that were correctly identified by the model. Put another way, of all the people that actually terminated - how many did the model correctly identify. Precision & recall are just one of the many metrics that One AI supports. If you or your team is more familiar with another method for measuring performance, we most likely already support it.
One Model is glad to work with your team in refining your algorithms to build strong predictive models and ensure you have the confidence to interpret the results.

Summary
Machine Learning and Data Science are extremely valuable tools that should be a welcome conversation topic and an important part of project roll-out plans. People Analytic professionals owe it to their companies to incorporate these tools into their decision-support capabilities even if they do not have access to internal data scientists. Care should be taken to ensure all predictive models are transparent, free from bias, and can be proven so by your analytics vendor.
Want to Learn More?
Contact One Model and learn how we can put leading-edge technology in your hands and accelerate your People Analytic initiatives.

